





Cuando dos años de trabajo académico desaparecen con un solo clic
El uso de herramientas de inteligencia artificial se ha vuelto cotidiano en la academia, pero no está exento de riesgos. Este artículo analiza un caso reciente publicado en Nature en el que un investigador perdió dos años de trabajo académico tras un cambio en la configuración de privacidad de una plataforma de IA. A partir de esta experiencia, se reflexiona sobre los límites de estas herramientas como espacios de trabajo y la importancia de mantener prácticas sólidas de respaldo y gestión de la información científica.

El café y el microbioma intestinal: evidencia científica de una interacción específica
El café es una de las bebidas más consumidas en el mundo y, durante años, se ha asociado con diversos beneficios para la salud. Pero ¿sabías que también podría influir directamente en las bacterias que viven en tu intestino? Un estudio reciente publicado en Nature Microbiology analizó datos de decenas de miles de personas y encontró que el consumo habitual de café está estrechamente relacionado con la presencia de una bacteria intestinal específica: Lawsonibacter asaccharolyticus. Este hallazgo ofrece una nueva perspectiva sobre cómo lo que bebemos a diario puede modificar nuestro microbioma y, potencialmente, nuestra salud.
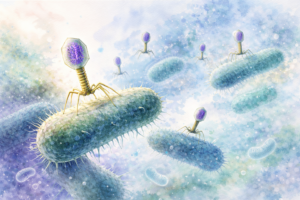
Construyendo virus desde cero para combatir superbacterias
La resistencia a los antibióticos es una de las mayores amenazas para la salud global. Frente a este desafío, científicos de New England Biolabs (NEB®) y la Universidad de Yale han desarrollado el primer sistema completamente sintético para diseñar y construir bacteriófagos —virus que infectan bacterias— desde cero. Utilizando información digital de ADN y una innovadora plataforma de ensamblaje genético, esta tecnología permite crear virus altamente específicos capaces de atacar bacterias resistentes como Pseudomonas aeruginosa. Este avance acelera la investigación en fagoterapia y abre la puerta a terapias más seguras, precisas y escalables contra las llamadas “superbacterias”.

